









In the field of Intensive Care Medicine, better survival rates have been the result of improved patient care, early detection of clinical deterioration, and prevention of iatrogenic complications, while research on new treatments has been followed by an overwhelming amount of disappointments. The origins of these fiascos are rooted in combined methodological problems – common to other disciplines, and in the particularities of critically ill patients. This paper discusses both aspects and suggests some options for the future.
En el ámbito de la medicina intensiva, el aumento de la supervivencia ha venido de la mano de la mejora de los cuidados, la detección precoz del deterioro clínico y la prevención de la iatrogenia, mientras que la investigación de nuevos tratamientos se ha seguido de una abrumadora serie de decepciones. Las raíces de estos fracasos hay que buscarlas en la conjunción de problemas metodológicos –comunes a otras disciplinas– y las particularidades de los pacientes críticos. En este artículo se exploran ambos aspectos y se sugieren algunas vías de progreso.
The ultimate goal of clinical research is to improve people's health. In order to achieve this goal, the studies on therapeutic and preventive interventions should be aimed at1 obtaining a relevant goal for the clinical decision-making process2; be based on the appropriate methodology in order to minize random and systematic errors3; be exposed comprehensively and on the right format for the decision maker, and, eventually, wisely implemented toward patient care (Fig. 1).4 Taking false stepts in any of these four (4) stages is a total waste of clinical research.1–3
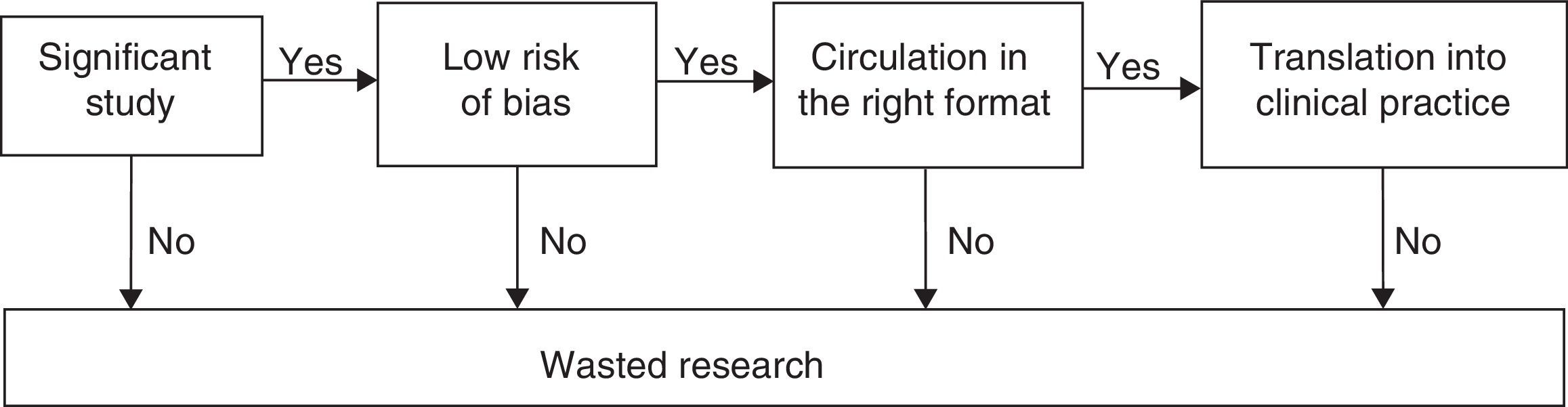
According to available data, the volume of wasted clinical research is significant: between 30% and 50% of all randomized trials have important methodological mistakes1,4; the rate of non-replicated studies is above 50%5–8; most researches available cannot be used,1,9–11 and, at one time or another, 40% of the patients receive therapies still not recognized as effective by the actual scientific standards.2,12,13
In the intensive care setting, important achievements have been made such as reducing the mortality rates associated with the acute respiratory distress syndrome (ARDS),14 or sepsis.15 However, these advances have been the result of improvements made in healthcare, early detection of clinical deterioration, and iatrogenia,16,17 whereas a large number of randomized trials have turned out negative, or with an unexpected increase of mortality rates18–23 (Table 1). This situation has made some influential researchers question the European regulations on clinical trials,24 and even the suitability of randomized clinical trials in the intensive care setting.17,25–28
Studies conducted in critically ill patients showing an increased mortality rate in the experimental group.
| Study (year) | Intervention | Patients | Mortality RR |
|---|---|---|---|
| Hayes et al. (1994)113 | Increased oxygen delivery | General critically ill patients | Hospital mortality RR 1.58 (95% CI 1.01, 2.56) |
| Takala et al. (1999)19 | Growth hormone | General critically ill patients | Hospital mortality (multinational substudy) RR 2.4 (95% CI 1.6 to 3.5) |
| Finfer et al. (2009)23 | Strict control of glycemia | General critically ill patients | Mortality at 90 days OR 1.14 (95% CI 1.02 to 1.28) |
| Gao Smith et al. (2012)20 | β-2 antagonists | ARDS under mechanical ventilation | Mortality at 28 days RR 1.47 (95% CI 1.03 to 2.08) |
| Perner et al. (2012)22 | Hydroxiethylal starch | Severe sepsis | Mortality at 90 days RR 1.17 (95% CI 1.01 to 1.36) |
| Ferguson et al. (2013)21 | High frequency oscillatory ventilation | Moderate-serious ARDS | Hospital mortality RR 1.33 (95% CI 1.09 to 1.64) |
| Heyland et al. (2013)73 | Glutamine | Critically ill patients with mechanical ventilation and multiple organ failure | Mortality at 28 days OR 1.28 (95% CI 1.0 to 1.64) |
95% CI: 95 per cent confidence interval; OR: odds ratio; RR: relative risk; ARDS: acute respiratory distress syndrome.
This first article from the series Methodology of research in the critically ill patients,discusses the deficiencies within the “chain of research” that may partly explain the fiascos resulting from the comparative effectiveness studies (CES) conducted in the intensive care setting; we will also be dealing with the particularities of clinical research in critically ill patients that may have contributed to these fiascos; finally, we will be taking a look at possible ways to improve the future of clinical research. Other methodological problems, big data research,29 and ethical-legal aspects of clinical research will be discussed in future articles within this series.
Significant outcomesPreclinical research is essential if we want to understand the physiopathology and development of effective therapies for the management of critically ill patients.30 For instance, the confirmation of the acute pulmonary injury in ventilated animal models with high volumes31 was successfully translated into the clinical practice and made up the foundation of the actual protective ventilation methods. However, up to 75–90% of all the results from preclinical research published in high profile scientific journals – usually of etiological and physiopathological type, are not reproducible7 and, as of today, only a minimum part has been translated into substantial innovations that can be used at the patient's bedside.32
As it occurs with preclinical research, the traditional clinical research focuses on analyzing the different biological manifestations of the disease (such as the cardiac output or the plasma cytokine levels). The problem here is that the scientific literature has continuously separated these physiopathological results (of interest for researchers) from the clinical results (of interest for the patient). Two of the most widely known fiascos here are the strategies to produce supranormal oxygen delivery,33 or the most recent early goal-oriented hemodynamic resuscitation.34,35
From the perspective of patient-focused clinical research,36 these outcomes should be considered surrogate outcomes (or indirect evidence) of the truly significant clinical outcomes for the decision-making process such as survival, extubation after mechanical ventilation, quality of life after hospital discharge, or costs.37 If this indirect evidence does not translate into improved significant clinical outcomes, it leads to wasted clinical researches.
Another useless piece of clinical research occurs when one study poses one research question with relevant clinical outcomes on which we already have satisfactory scientific evidence.1,38 It has been estimated that 50% of the studies are designed without any references to prior systematic reviews,39 with the corresponding risk of generating redundant publications. For example, Fergusson et al.40 used one cumulative meta-analysis of 64 trials published between 1987 and 2002 to show that the effectiveness of aprotinin had already been established back in 1992 after conducting the 12th trial; this means that the following 52 trials could have been avoided with an adequate systematic review. Other than unnecessary, and ethically questionable, this clinical research is redundant which has led the civil society and some financial institutions to require systematic reviews on the topic under study before starting a new clinical trial.3,41,42
There has been a lot of discussion on what the most adequate clinical outcome is for clinical trials with critically ill patients.18,43–46 All-cause mortality is the most relevant outcome par excellence. In any case, mortality should relate to an adequate deadline that is consistent with the study pathology (for instance, mortality at 28 or 90 days),45 while taking into consideration the possible impact that the limitation of life-sustaining treatment (LLST) policies may have.
One of the difficulties of mortality is its dichotomic nature that increases dramatically the requirements of the sample size, particularly in situations of low incidence rates. Some have tried to solve this issue by developing combined outcomes (composite endpoints) such as the appearance of “death, infarction, or urgent reperfusion”, or “death or organic dysfunction”.47 However, combined outcomes are, sometimes, hard to interpret, can be easily manipulated by the researcher, and promote a rather optimistic standpoint of the results, which is why we should be cautious when it comes to interpreting them.48,49 For example, the use of the combined outcome “death, infarction, or urgent reperfusion” does not make a lot of sense if the differences reported are due to the differences in reperfusion only.
Mortality is the only relevant outcome for the patient. Issues such as the ICU stay, the number of days on mechanical ventilation, or the quality of life after hospital discharge50 are other important outcomes as well that should be taken into consideration by the clinical practice guidelines when it comes to establishing recommendations.
In comparative studies of antimicrobial agents in critically ill patients, the traditional clinical outcomes have serious limitations. For example, mortality can be partially due to the infectious process. Estimating the mortality rate that can be attributed to this can be more useful than making an estimate of crude mortality, particularly, when various causes of death and comorbidity coexist.51 Nevertheless, we should remember that the attributable risk does not measure how strong the correlation is (as relative risk or relative risk reduction do), but the impact, whose value is based on the patient's baseline risk. Other common outcomes such as the clinical healing rate, or the duration of infection are highly subjective, since the symptoms can be due to other intercurrent events. On the other hand, the comparative studies of antimicrobial strategies require combined assessments of relevant outcomes for the patient (mortality, healing, adverse events) and other relevant outcomes for society (duration of treatment, appearance of resistances). The Desirability of Outcome Ranking/Response Adjusted Days of Antibiotic Risk (DOOR/RADAR) methodology allows us to make combined comparisons of the distribution of these outcomes, which would eliminate some of the problems that non-inferiority studies have in this field.52,53 Although it has been proposed as the methodology of choice for the coprimary analysis of studies for the improvement of antibiotic strategies, this methodology also shares the limitations of studies with combined outcomes, its interpretation is susceptible to manipulation by researchers, and one negative outcome will not always rule out the non-inferiority of the experimental therapy.54,55
Small studiesThe lack of statistical power to detect reasonable effects may partly explain the negative results obtained in the studies conducted in critically ill patients.56,57
Harhay et al.57 reviewed randomized trials conducted in ICUs and published in 16 high-impact scientific journals. Out of the 40 studies that analyzed mortality, 36 were negative and only 15 were large enough to be able to detect 10% absolute reductions in the mortality rate. One of the determinant factors of these results was a wrong estimate of the size of the sample based on treatment effect estimates that were a little too optimistic. This poses an ethical problem if we consider that patients are the subjects of experimentation trials that do not have enough resources to meet the goals.58 On the other hand, part of these negative results may be due to “false negatives”, which could discourage future studies in a promising field.
Paradoxically, on top of providing type II errors (false negatives), small studies may lead to false positives that will not be confirmed in subsequent studies. As a matter of fact, when the number of patients is small (such as at the beginning of the recruitment stage of a trial), the treatment effect estimate is highly unstable and usually leads to spurious results (false positives and false negatives).59,60
Typically, these false positives (“randomized maximum”) are consistent with an improbable effect estimate.61
The randomized maximums characteristic of small studies may explain most of the fiascos of clinical research in the intensive care setting. For example, in a randomized trial of patients operated of severe pancreatitis, 30 patients were randomized to early jejunal nutrition (within a 12 hour-time frame after surgery), and the remaining patients were randomized to the control group. The mortality rate was 3.3% in the experimental group, and 23% in the control groups (relative risk 0.14; 95% confidence interval [95% CI] 0.02–0.81; p=0.03).62 Aside from all possible biases, these results should raise some eyebrows for two reasons. In the first place, it does not seem very realistic that right at beginning of enteral nutrition (within the first 12h), the mortality rate went down 86% (relative risk, 0.14). Secondly, the size of the sample estimated to detect one “reasonable” effect of 30% (5% significance level, and 80% statistical power) is 518 patients per group. Both the small size of the sample (below the optimal size of information63) and the improbable magnitude of the treatment effect are strong indicators that we are witnessing a randomized maximum. This impression was confirmed by a subsequent meta-analysis64 based on 12 trials and 662 patients that compared early enteral nutrition to late enteral nutrition in general critically ill patients and did not find any significant differences in the mortality rate (relative risk, 0.76; 95% CI 0.52–1.11).
Lastly, small studies usually pose methodological issues that make them more prone to bias, which may contribute to overestimating the effect sizes.
There is empirical evidence that this happens in clinical research in the management of critically ill patients. This is the reason why Zhang et al.65 studied 27 meta-analyses (317 studies) of trials conducted in critically ill patients in order to analyze the mortality rate. They confirmed that small studies (<100 patients per arm) provided worse quality results in issues such as generation and concealment of the randomization sequence, losses to follow-up, intention-to-treat analyses, or blinding and, overall, they overestimated the treatment effect in almost 40%.
The problem with small studies is intimately associated with the early interruption of clinical trials after benefits have been confirmed. Usually, while a clinical trial is being conducted, other intermediate analyses are being conducted as well in order to stop any new patient recruitment whenever there is clear evidence of superiority, toxicity, or futility. Such a practice opens the possibility of interrupting a clinical trial on the grounds of a randomized maximum only (with the corresponding effect overestimate).66,67 One example of this is the OPTIMIST study68 that was analyzing the effect of tifacogin treatment in patients with severe sepsis and coagulopathy. The first intermediate analysis with the first 722 patients recruited showed a significant reduction of the mortality rate in the experimental group (29.1% vs 38.9%; p=0.006) that disappeared after the final analysis recruited 1754 patients (34.2% vs 33.9%; p=0.88).
SubgroupsTrials provide average results of the effectiveness of treatment on the entire cohort of patients included in the study. However, not all patients included in the study benefit the same from the treatment: some patients show the treatment adverse events (“damaged”), others have adverse events despite the therapy (“condemned”), and other patients would have never shown any adverse events in the first place, which is why the treatment would have been superfluous (“immune”).69 The analysis of stratified results by demographic data, levels of severity, or comorbidity allows us to identify those subgroups that may benefit the most or suffer damages as a consequence of treatment.
With all this, the homogeneous distribution of the prognostic variables among the different arms of the trial within each subgroup is not guaranteed, and the subgroup analysis associates significant risks.70 In a recent meta-epidemiological study70 only 46 out of the 117 declared subgroups were backed by their own data; only 5 out of these 46 subgroup findings had, at least, one corroboration attempt, and none of the corroboration attempts reached a significant p value in the interaction test.
Other methodological problems in critically ill patients, such as the generation and concealment of the randomization sequence, the attrition bias, or blinding will be closely analyzed in other papers of the series.
Selective or inadequate discussion of resultsFor comparative effectiveness studies to become useful they not only need to be relevant, well-designed, and executed. It is also essential that the evidence generated makes it to the clinical decision-maker and, ultimately, is implemented in his patients.
It is estimated that 50% of the studies conducted are never published in a paper1 and the part that, ultimately, is published is an over-representation of the studies with positive results, and under-representation of the treatment adverse events (publication bias). For example, at one time or another, glutamine supplements were recommended by certain clinical practice guidelines in patients who suffered burns and traumatic injuries71; one Cochrane meta-analysis conducted in general critically ill patients found traces of publication bias,72 and one large, well-designed trial found increased mortality rates in critically ill patients with multiple organ failure.73
The publication bias lies at the root of resistance from the sponsors who do not with to publish unfavorable results and hide themselves behind permissive regulations that entitle them to conceal the results of studies,74 and at the editors’ tendency to preferably publish studies with positive results. However, several studies indicate that researchers themselves implement some sort of self-censorship that leads to never publish negative results.74 The severity of this situation has given birth to initiatives such as the Alltrials campagin,75 or the James Lind initiative41 that promote the publication of all available evidence and encourage patients to never participate in trials if the publication of all the results is not guaranteed.3,75
On the other hand, not all outcomes studied are ultimately published which generates some sort of “intra-study publication bias”. Chan et al.76 said that in up to 62% of the studies whose protocol had already been registered, the paper had finally been published with, at least, one primary outcome changed, introduced, or omitted; also, the statistically significant outcomes had more chances of being communicated that the non-statistically significant ones. For example, in one comparative study of fluid therapy with saline solution vs hydroxyethyl starch (HES) in a group of traumatized patients,77 the conclusion was that “the HES causes less renal damage and a significantly lower lactate clearance compared to the saline solution”. In the previous registry of the trial (http://www.isrctn.com/ISRCTN42061860), the authors had marked two (2) primary outcomes, and seven (7) secondary outcomes. However, Reinhart and Hartog,78 say that three (3) of the outcomes published were not part of the registry, among them, acute renal damage and lactate clearance, that happen to be the paper main results. This selective communication of the outcomes tends to favor false positives and contributes to over-estimating the benefits of the treatments published in the medical literature.
Lastly, even if they are published, the results can be manipulated or not be exposed very clearly, which makes the result replication difficult to achieve, and complicates their validity and applicability making them useless.79 It is well-known that studies promoted by the pharmaceutical industry significantly over-estimate the effectiveness of experimental treatments compared to other studies promoted by non-lucrative entities (“sponsor bias”).80 This is a problem that has aggravated during the last few years due to the so called “predator publications”, a business model based on free access journals funded with the authors’ fees without proper peer reviews, or other quality control measures.81–83
The more and more common requests that journals make to the authors of papers to provide crude data, so they can be reviewed by statisticians, together with the proposal made by the Institute of Medicine (IOM)84 of providing one shared analysis of the primary data of randomized trials seem to pave the way to address some of the actual deficiencies and reduce wasted researches. The latter proposal has recently been adopted by the International Committee of Medical Journal Editors (ICMJE),85 yet only a few medical journals follow it (Fig. 2).
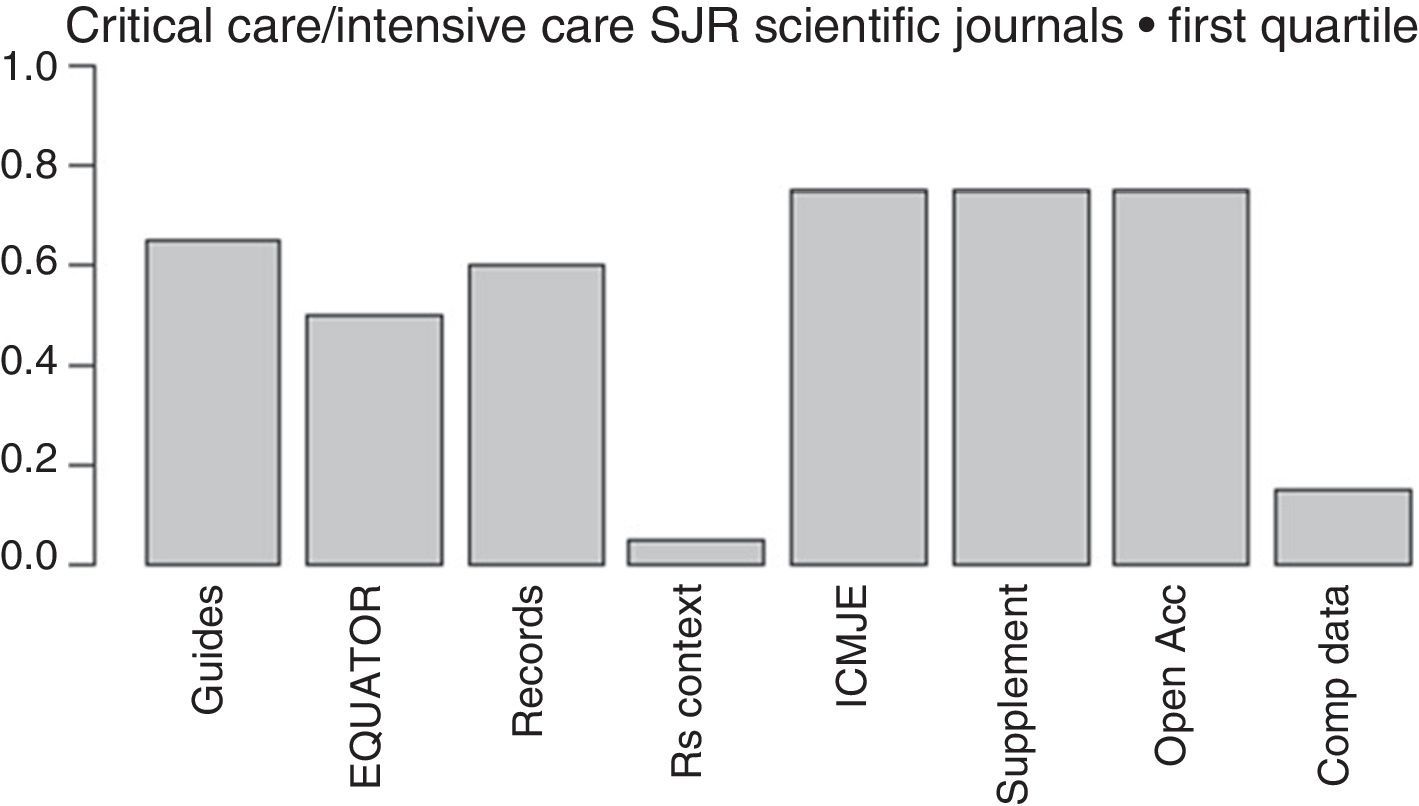
Initiatives from the intensive care journals to improve the chain of clinical research.
Measures aimed at reducing wasted clinical reseaches included in the regulations for the authors of intensive medicine journals indexed by SJR within the first quartile (year 2015). From left to right: mentions some guidelines presenting the results; mentions some EQUATOR guidelines; mentions the prior trials registry, or systematic reviews; suggests systematic reviews for the contextualization of original papers; recommends checking through the ICMJE official website; allows the online publication of additional material; mentions some form of free access; mentions policies to improve the shared use of data. Shared d.: shared data; EQUATOR: Enhancing the QUAlity and Transparency of Health Research; ICMJE: International Committee of Medical Journals Editors; Open Acc: Open Access; SR: systematic review; Supplement: additional material; SJR: Scimago Journal Reports.
Lastly, one of the most important advances made during the last few years when it comes to disclosing the results of a clinical research is the EQUATOR initiative,86 that has produced guidelines for the publication of several types of studies such as the CONSORT (for clinical trials), the PRISMA (for meta-analyses), or the STARD (for diagnostic studies) that promote the transparent disclosure of results and let the reader be the judge on how credible the results really are.86 Unfortunately, the number of intensive medicine journals that recommend its use is still scarce (Fig. 2).
Implementing the resultsThe fourth link in this chain of clinical research is the decision of whether to implement, or not, the results that come from scientific evidence. The question here is whether to take a leap from the evidence obtained from selected patients (among which patients with comorbidities have already been excluded) under the optimal healthcare conditions, until making the clinical decision in every patient (with his own comorbidity and preferences) in a completely different healthcare setting.87,88
The clinical guidelines based on the evidence provided are of great help when it comes to establishing individual recommendations. These days, the GRADE approach (Grading of Recommendations Assessment, Development and Evaluation) is considered the standard of reference when it comes to establishing the degree of evidence and the strength of recommendation.89,90 However, not all clinical practice guidelines are equally reliable. The non-critical implementation of old hierarchies of evidence based on a single clinical outcome, that automatically puts clinical trials with high quality evidence on the same level, led to think that high-flow hemofiltration for the management of sepsis was being backed by high-quality evidence, which also led to say that it should be implemented in all patients with acute renal failure.91 A few years would still have to pass until subsequent studies would confirm that high-flow therapy was futile.92
Additional difficulties of comparative effectiveness studies in critically ill patientsAdded to the aforementioned deficiencies common to other disciplines, we find the peculiarities of clinical research in the critically ill patient that, to a great extent, make conducting and interpreting studies a little more complicated.
The most significant trait is the great heterogeneity of patients included in the trials. The common diagnoses of critically ill patients (such as ARDS or sepsis) are really syndromes that need periodic re-defining93,94 including a great variety of conditions. As an example of this, less than half the patients diagnosed with ARDS using the criteria defined by the Berlin Definition93 show diffuse lung injury in the autopsy—the classic anatomopathological correlate of ARDS.95 Added to this heterogeneity among patients, we find the rapidly changing physiopathology of the disease within the same patient, as it is the case with sepsis. Under these conditions, it does not seem very reasonable to expect that one single treatment will be effective for different forms of ARDS, or equally effective in hyper-inflammatory phase sepsis and immune deficient sepsis.26,27
Secondly, in the critically ill patient there are a wide variety of therapies working at the same time, and a high prevalence of comorbidity with the corresponding probability of interactions and implementation of diagnostic procedures or additional therapeutic procedures (cointervention)—sometimes in a subtle way.96–99
Lastly, the intensive monitoring and continuous adjustments of therapies delivered in the intensive care setting are an additional difficulty when it comes to designing a right control group that is representative of the usual clinical practice. As a matter of fact, within the ICU setting, therapies are dosed in a flexible way based on the situation of every patient (such as hemodynamic changes or pulmonary mechanics). If these interventions become fixed in a strict protocol, then in both arms of the study we can end up creating subgroups of patients who receive doses of therapy that are not consistent with the standard of clinical practice. On top of compromising the study external validity, this mismatch with the standard of clinical practice (practice misalignment)25,100 causes new problems of interpretation and can be detrimental for certain patients.
For example, in the Acute Respiratory Distress Syndrome (ARDS) Clinical Trials Network low-tidal-volume (TV) trial (ARMA)14 a series of patients with ARDS were randomized to mechanical ventilation with a tidal volume (TV) of 6ml/kg vs 12ml/kg. When the study was conducted, the usual practice was to reduce the TV as the pulmonary distensibility and the airway pressures were going down too. Thus, the randomization generated one subgroup of more severe patients where a TV of 12ml/kg was too much, and another subgroup of less severe patients where a TV of 6ml/kg was lower than the standard of clinical practice. Subsequent studies showed that in patients whose pre-randomization distensibility is lower, a higher TV associated higher mortality rates, compared to patients treated with low volumes (42% vs 29%). On the contrary, in patients with higher distensibility, a reduced TV increased the mortality rate (37% vs 21%).100
In these conditions, the effect of treatment is not compared to the results obtained in the real clinical practice, but with artificial experimental conditions instead that do no genuinely reflect the real effectiveness of treatment.
Individualization of intensive care medicine and precision medicineIndividualized medicine is not a new finding. The stratification of risks and the development of rules of clinical prediction have a long tradition in the intensive care setting and have facilitated the identification of relatively homogeneous groups of patients, and established recommendations adjusted to the risk/benefit ratio of every individual.87,101 During the last few years, the individualization of therapies has benefited from the development of new biological markers—both prognostic and in response to therapy.102,103
Another step in this individualization of therapies would be “precise” prescriptions on the grounds of genetic, proteomic, and metabolic characteristics of patients (“precision medicine”).104 This initiative has been very successful in some disciplines, especially oncology (such as in her-2 positive breast cancers, EGFR-positive lung cancers, etc.). These advances made have created the expectation that precision medicine will allow us to identify the therapeutic targets, and obtain homogeneous groups of critically ill patients, thus avoiding false negatives due to the inclusion of patients who cannot benefit from a given therapy.104
This idea has been enthusiastically welcomed by those researchers who think that at the root of CES fiascos in intensive medicine lies the proteiform nature of the critical condition and the heterogeneity of responses to different therapies, and propose redirecting clinical research toward precision medicine. Usually this proposal is accompanied by a defense of the supremacy of physiopathologic reasoning, and by the generation of new evidence from additional data (big data), rather than evidence from randomized trials.17,25,27
At this point, we should make a few clarifications. In the first place, the opposition between precision medicine—based on the patient's physiopathology and individual characteristics, and evidence-based medicine—obtained from groups of patients, is merely apparent,105 since both need each other mutually. As a matter of fact, among the promising findings of pre-clinical research and its integration in clinical practice, assessing the validity (analytical or critical) and clinical utility of the possible applications (test or treatments) is required.106 This translational process that goes well beyond the bench-to-bedside paradigm includes, necessarily, randomized clinical trials, research syntheses (systematic reviews, meta-analyses, decision-making analyses), and evidence-based clinical practice guidelines107–110 (Fig. 3). Getting to know the physiopathology is essential for a correct design of randomized clinical trials and to assess the biologic plausibility of the findings that come from clinical research27,111,112; however, we should remember here that its exclusive use for the decision-making process has generated significant damage to patients—something shown in large randomized clinical trials only19–23,73,113 (Table 1).
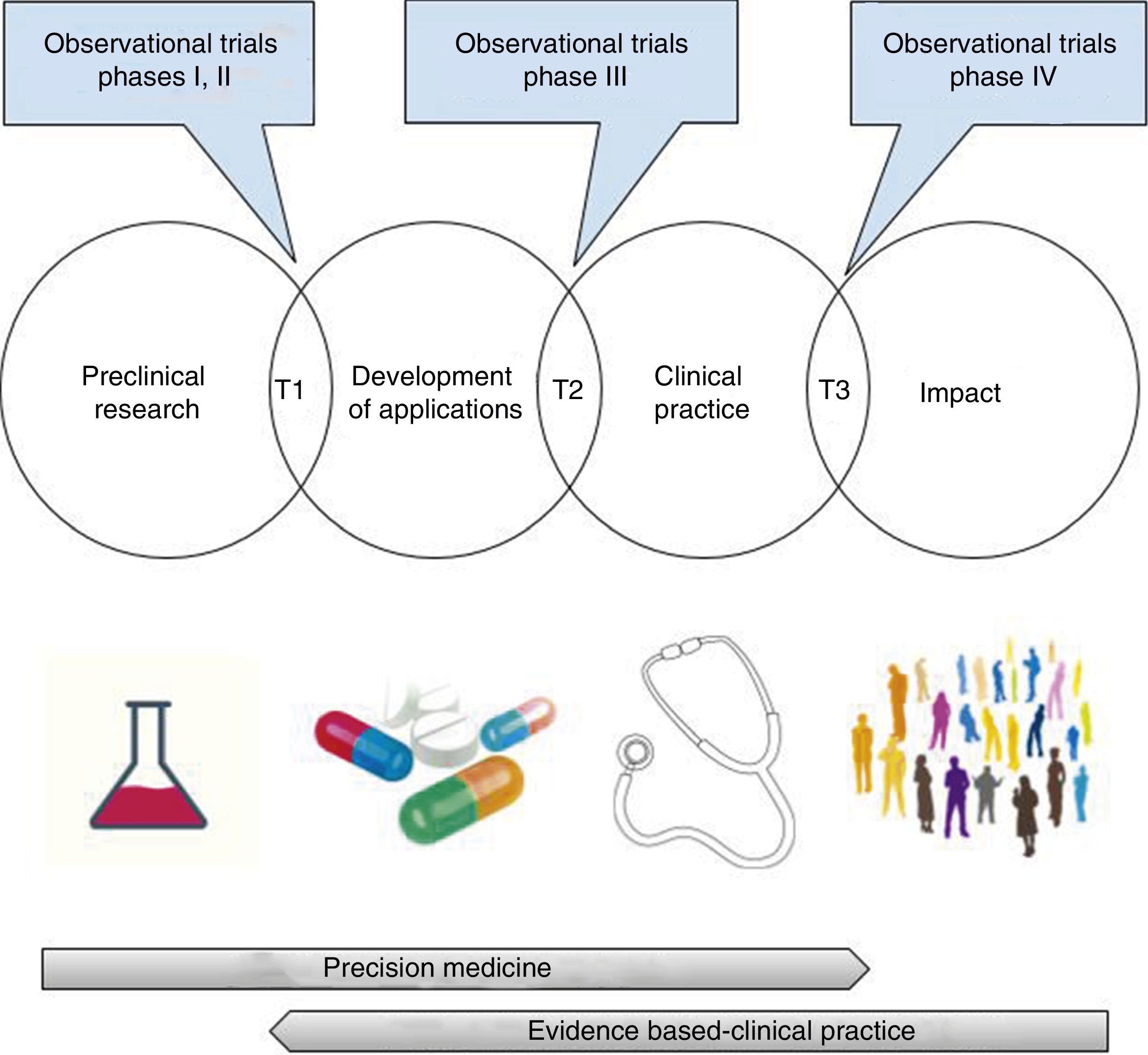
Translational research: from the lab to the impact it has on health.
T1-T3: translational research type 1-type 3.
Images obtained under CC0 license through pixabay (https://pixabay.com).
Secondly, the era of precision medicine still has not made it to intensive medicine,32 and there are still some problems that need to be solved first before it is accepted as a viable proposal.104,114,115 The difficulties obtaining predictive biomarkers of treatment response in the clinical practice are significant, especially in the rapidly changing physiopathological conditions of critically ill patients. For example, although that there are over 1000 publications on genetic polymorphisms in sepsis, we still have not found one diagnostic test valid enough and available at the patient's bedside capable of matching one specific genotype with its corresponding therapy.104 On the other hand, the available body of evidence on this field has significant weaknesses: most studies are based on finding significant p values without a prior hypothesis; they usually use convenience samples with a high risk of selection bias, have an insufficient control of the confounding variables, and a low rate of reproducibility.6 When it comes to its viability, the actual computing infrastructure, and legal base needed to manage all the necessary data for precision critical care medicine to become a reality today is clearly insufficient,29,104 and doubts on its economic sustainability remain; an example of this is the recent decision made by Medicare and Medicaid to not refund any pharmacogenomic prescriptions of warfarin, yet despite the benefit provided to a small group of patients with the genomic variant.116 Finally, far from dodging the topic of logistics issues in large trials, the inherent need of precision medicine aimed at evaluating individualized therapies translates into more demanding inclusion criteria with the corresponding reduced recruitment times and increased costs of performance.104
For all this, the development of precision medicine in the intensive care setting should not stop the performance of new and improved clinical trials.117,118
Better clinical trialsRandomized trials, and especially those conducted in critically ill patients, have limitations such as their detachment from the “real world” (due to strict selection criteria, the academic setting, and the protocolized treatment), and the difficulties (both legal and logistics) recruiting large enough samples.17,119
The gap between the real clinical practice and clinical trials creates a problem of external validity that has been approached through the design of pragmatic trials. Unlike explanatory trials (or efficacy studies), focused on maximizing the possibilities that a therapy has of showing the effect it causes, pragmatic studies (or effectiveness studies) are focused on evaluating the effect of the intervention under the conditions of clinical practice, which makes them more representative and gives them certain information about the real effectiveness of the intervention (Table 2).120
Characteristics of efficacy studies vs effectiveness studies.
| Explanatory trial | Pragmatic trial | |
|---|---|---|
| Goal | Determine efficacy | Determine effectiveness |
| Context | Professional researchers | Standard clinical practice |
| Selection criteria | Strict (internal validity is the priority) | Wide (external validty is the priority) |
| Size of the sample | Usually intermediate-small | Large (thousands of patients) |
| Outcomes | Usually intermediate | Relevant outcomes for the patient |
On the other hand, meta-analyses of individual data give us the opportunity of exploring homogeneous subgroups of patients with greater statistical power without having to give up traditional adjustment techniques.35
In the absence of randomized trials, the available trials are low-quality trials,121 or lack enough statistical power (like for detecting rare events); observational trials based on secondary analyses of registries may be adequate; however, these trials are limited by the quality and number of variables collected.122
On the other hand, observational trials have the problem of confounding by indication (the patients of both the experimental and control groups have different prognoses due to known or unknown confounding variables). The statistical adjustment uses the propensity score estimator for the treatment effect and, in general, provides results that are consistent with those from randomized trials; however, sometimes, the results are contradictory, and there is no reliable way to predict these mismatches.123 For all this, observational trials do not seem right for the assessment of small-effect interventions.124,125
New modalities of clinical trials have been developed recently that may help work out some of these limitations. Here we should mention the cluster randomized crossover trials with binary data that have great potential for the assessment of standard interventions in the intensive care setting aimed at reducing the mortality rate.126–129
On the other hand, the cohort multiple randomized controlled clinical trial combines the strengths of randomized trials—internal validity, and those of observational trials—representative consecutive sampling, comparisons with real clinical practice, large recruitment processes, and less cost.125,130 This type of design can benefit as well from real time data mining through electronic surveillance systems (“sniffers”)—a technology that immediately tells the researchers about the existence of patient with inclusion criteria, which, by the way, has doubled the speed of recruitment in a trial on sepsis.131
Lastly, the new adaptative designs may be especially useful when subgroup effect is suspected (susceptibility markers).132 This design is being used in a large European trial of community-acquired pneumonia (AD-SCAP) aimed at testing different combinations of antibiotics, steroids, and ventilation strategies (ClinicalTrials.gov NCT02735707). Using a complex procedure based on great amounts of data, one computing platform adaptatively allocates patients with distinctive traits of the disease to the most promising therapies for each and every one of them. These characteristics suggest that platform studies may be the first step ones toward precision medicine, since they work with heterogeneous groups of patients, while at the same time, allow real time analysis of specific subgroups and reduce the rate of false negatives due to the differential effects of treatment.
CorollaryThe results of clinical research in the critically ill patient during the last few decades have little to do with the expectations generated on this regard. This has to do not only with the singularities of the critically ill patient, but also with deficiencies that need to be improved in the chain of clinical research. The future development of a hypothetically precise critical care medicine is promising but, in the meantime, we should be taking measures to stop wasting efforts in clinical research9,10,133–135 (Table 3).
Initiatives to improve the relevance, quality, and spreading of clinical research.
| Initiative/resource | Goal |
|---|---|
| James Lind41 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC539653/ | Promote better clinical trials: new trials in the context of systematic reviews; participation of patients in prioritization; participation in relevant clinical trials |
| https://clinicaltrials.gov/ https://www.clinicaltrialsregister.eu/ http://www.who.int/ictrp/en/ http://www.hkuctr.com/ https://www.crd.york.ac.uk/PROSPERO/ | Trial registries and systematic reviews |
| CASP International CASP España http://www.redcaspe.org/ | Training in critical reading of biomedical literature |
| GRADE http://www.gradeworkinggroup.org/ | Development of rigorous methodologies to elaborate clinical practice guidelines |
| Alltrials75 http://www.alltrials.net/ | Promote the publication of all clinical research |
| EQUATOR http://www.equator-network.org/ | Guidelines for a transparent disclosure of clinical research data |
| Evidence Alerts https://plus.mcmaster.ca/EvidenceAlerts/ | Selective disclosure of valid and relevant papers |
| Antimicrobial Stewardships Programs https://www.cdc.gov/getsmart/healthcare/implementation/core-elements.html | Improve the use of antimicrobial agents |
J. Latour is a member of CASP-España.
We wish to thank Mr. Juan B. Cabello, Mr. Vicente Gómez-Tello, Ms. Ana Llamas, Ms. Eva de Miguel, Mr. Juan Simó, and Mr. José Antonio Viedma for the critical teading of a former version of this manuscript. Usual disclaimer applies.
Please cite this article as: Latour-Pérez J. Investigación en el enfermo crítico. Dificultades y perspectivas. Med Intensiva. 2018;42:184–195.

